
Recurrent Neural Networks (RNN) Tutorial | Analyzing Sequential Data Using TensorFlow In Python
In recent times Deep Learning has almost replaced humans as part of computer programs and machine learning intelligence to keep up with the pace of industry standards it is being made mandatory for individuals working in the technical fields to get certifications like Artificial Intelligence Training for excelling in the career. So, Tensor Flow is Google’s open-source machine learning framework for programming in the data flow.
Define RNN? State it’s Working.
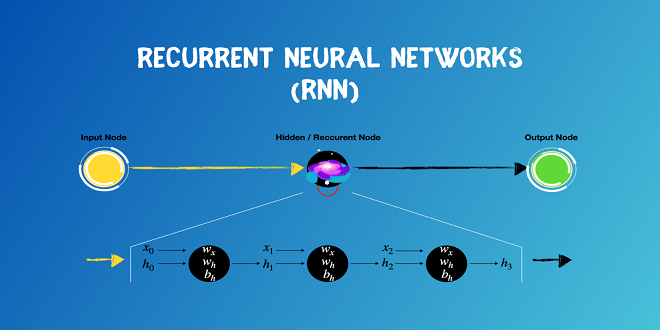
Recurrent neural networks (RNN) is a category of neural networks that are influential for modeling progression data such as time series or natural language. Schematically, a Recurrent Neural Network layer utilizes a for loop to iterate over the time steps of a progression, while retaining an internal state that encodes data about the timestamps it has discerned so far.
A Recurrent Neural Network is a degree of Artificial Neural Network, in which the relationship between various nodes constructs a directed graph to give a secular dynamic behavior. It assists to model sequential data that are originated from feedforward networks. It works likewise to human brains to deliver. A recurrent Neural Network is useful for an independent car as it can avoid a car accident by foreseeing the trajectory of the car.
Visualize a simple prototype with only one neural on feeds by the batch of data. In a conventional neural net, the model generates the output by multiplying the input with the weight and the activation process. With a Recurrent Neural Network, this outcome is sent back to itself a number of times. We call the time step the fraction of time the output becomes the input of the subsequent matrix multiplication.
Recurrent Neural Network (RNN) enables you to model memory units to maintain data and criterion-short-term reliance. It is also used in time-series forecasting for the identification of data correlations and structures. It also helps to elicit prophetic results for sequential information by delivering identical behavior as a human brain.
The structure of an Artificial Intelligence Certification Neural Network is moderately simple and is mainly about matrix proliferation. During the first step, inputs are multiplied by originally random weights, predisposition is altered with an activation function, and the output values are used to make a revelation. This step gives a notion of how far the network is from reality.
The metric pertained is loss. The greater the loss function, the dumber the criterion is. To enhance the proficiency of the network, some optimization is obliged by adjusting the weights of the net. The stochastic slope descent is the technique assigned to change the values of the weights in the right path. Once the adjustment is done, the network can use another package of data to test its new knowledge By Sprintzeal.
The error, fortunately, is lower than recently, yet not insignificant enough. The optimization, step is completed iteratively, until the mistake is minimized, i.e. no additional data can be taken out.
The problem with this type of category is, it does not have any memory. It means the input and output are autonomous. In different words, the prototype does not look after what came before. It raises some questions when you need to foresee the time series or verdicts because the network needs to know the historical data or past words.
Recurrent Neural Network is widely used in text inspection, image captioning, emotion analysis, and machine rendition. For example, one can use a movie survey to comprehend the feeling the spectator discerned after watching the movie. Automating this task is extremely useful when the movie company does not have adequate time to review, label, consolidate, and evaluate the reviews. The machine can do the job with a greater level of accuracy.
Theory and Conclusion
Recurrent Neural Network is deemed to carry the data up to time however, it is quite tough to propagate all this data when the time step is too long. When a network has numerous deep layers, it comes to be untrainable. This crisis is called: disappearing gradient problem. If you remember, the neural network updates the weight utilizing the gradient downfall algorithm. The gradients grow smaller when the network advancement down to lower layers.
The slopes stay constant meaning there is no space for development. The model understands from a change in the slope; this modification affects the network’s output. However, if the distinction in the slope is too small (i.e., the weights shift a little), the network can’t discover anything and so the output. Hence, a network-facing fading away gradient problem cannot converge toward a decent solution.




